Nanbeige4-3B: Token Pipeline Breakthrough
Exploring how a 3B model achieves 30B class reasoning through innovative training techniques.
Evaluating a New Paradigm in Model Training
Can a 3B model deliver 30B class reasoning by fixing the training recipe instead of scaling parameters? Nanbeige LLM Lab at Boss Zhipin has released Nanbeige4-3B, a 3B parameter small language model family trained with an unusually heavy emphasis on data quality, curriculum scheduling, distillation, and reinforcement learning.
The research team ships two primary checkpoints, Nanbeige4-3B-Base and Nanbeige4-3B-Thinking, evaluating the reasoning-tuned model against Qwen3 checkpoints from 4B up to 32B parameters.
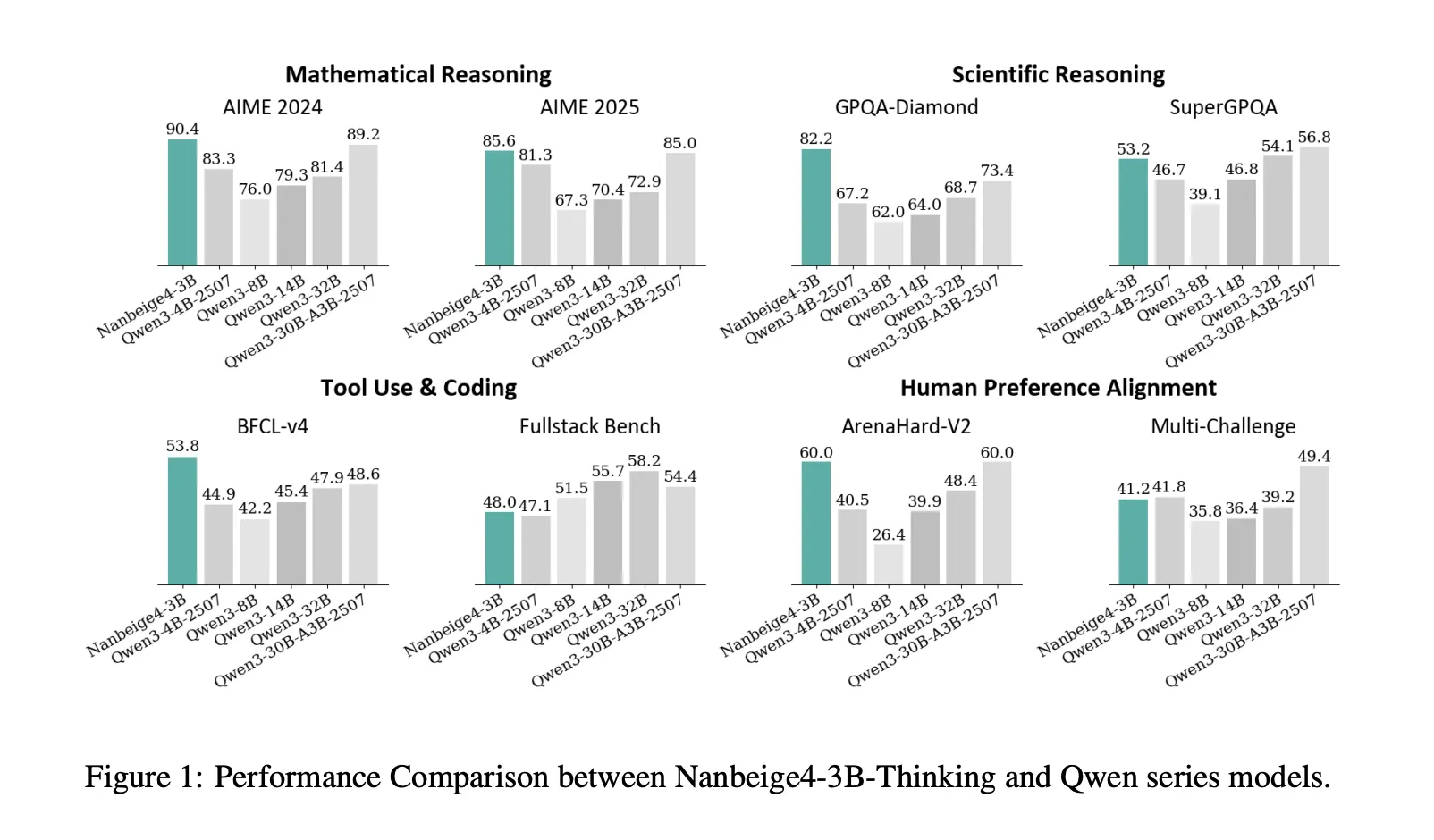
Benchmark Performance Metrics
On AIME 2024, Nanbeige4-3B-2511 reports 90.4, while Qwen3-32B-2504 reports 81.4. In GPQA-Diamond, Nanbeige4-3B-2511 reports 82.2, surpassing Qwen3-14B-2504's 64.0 and Qwen3-32B-2504's 68.7. These benchmarks illustrate how a 3B model can outperform significantly larger models.

The Training Pipeline: Innovative Techniques
Hybrid Data Filtering and Upsampling
For pretraining, the team combines multidimensional tagging with similarity-based scoring, leading to a training corpus of 23T tokens. This process involves filtering to 12.5T tokens of high-quality data and selecting a 6.5T higher-quality subset, demonstrating a distinct departure from traditional training methodologies.
FG-WSD: A Novel Data Scheduling Approach
Nanbeige4-3B introduces Fine-Grained Warmup-Stable-Decay (FG-WSD), concentrating on higher quality data during training's later stages. This approach emphasizes the quality curriculum instead of mere quantity.

In ablation studies, the model shows significant improvement in benchmarks like GSM8K, indicating the effectiveness of FG-WSD.
Multi-Stage Supervised Fine-Tuning (SFT)
The training approach uses staged SFT to enhance reasoning capabilities. The cold start begins with QA samples focused on math and code, followed by overall SFT focusing on general reasoning tasks. This multi-faceted training ensures improved performance in reasoning tasks.
Comparison Table: Performance Metrics
| Benchmark, metric | Qwen3-14B-2504 | Qwen3-32B-2504 | Nanbeige4-3B-2511 | |-------------------|-------------------|-------------------|-------------------| | AIME2024, avg@8 | 79.3 | 81.4 | 90.4 | | GPQA-Diamond, avg@3 | 64.0 | 68.7 | 82.2 | | Arena-Hard-V2, avg@3 | 39.9 | 48.4 | 60.0 |
Key Insights from the Research
- Reasoning Capability: The model demonstrates that smaller configurations can effectively rival larger models in reasoning capabilities through meticulous training strategies.
- Evaluation Techniques: A rigorous average sampling methodology ensures that the accuracy metrics are sound and reliable.
- Curated Training Data Pays Off: The deliberate scheduling of quality data in the training phases significantly impacts overall performance metrics.
For more insights, check the full research paper and model weights. The advancements made through the Nanbeige4-3B model show great promise for future developments in AI reasoning.
Сменить язык
Читать эту статью на русском